« Une horreur subalterne : la vaste Bibliothèque contradictoire »
« Bientôt, les écrivains ne se demanderont plus “Quel livre écrirai-je ?” mais “lequel ?” » – Kurd Lasswitz (cité par J. L. Bórges)
Jorge Luis Bórges ne s’est pas attribué l’invention de la bibliothèque universelle. Bien au contraire : il détaille la longue histoire de ce « caprice, ou imagination, ou utopie », dont on doit la préfiguration à Démocrite, et dont le « tardif inventeur est Gustav Theodor Fechner et Kurd Lasswitz est le premier à l’exposer ». Fechner (1801-1881) est considéré comme le père de la psychologie expérimentale contemporaine, où il a introduit des méthodes quantifiables et mathématiques. Lasswitz (1848-1910) était mathématicien et physicien ; non traduit et quasi inconnu en France1, on lui attribue la paternité de la littérature de science fiction allemande. Bórges écrit :
« Lasswitz, encouragé par Fechner, imagine la Bibliothèque Totale. Il publie son invention dans le volume de récits fantastiques Traumkristalle.
Lasswitz presse les hommes de produire mécaniquement cette Bibliothèque inhumaine qui organiserait le hasard et éliminerait l’intelligence (…). Tout sera contenu dans ces volumes aveugles. Tout, l’histoire minutieuse de l’avenir, Les Égyptiens d’Eschyle, le nombre précis de fois que les eaux du Gange ont reflété le vol d’un faucon, l’authentique et secret nom de Rome, l’Encyclopédie qu’aurait édifiée Novalis, mes rêves et mes demi-sommeils de l’aube du 14 août 1934, la démonstration du théorème de Pierre Fermat, les chapitres non écrits d’Edwin Drood, ces mêmes chapitres traduits dans la langue que parlèrent les garamantes, les paradoxes que conçut Berkeley sur le temps et qu’il ne publia pas, les livres de fer de Urizen, les épiphanies anticipées de Stephen Dedalus qui avant un cycle de mille ans ne voudraient rien dire, l’évangile gnostique de Basilide, la chanson que chantaient les sirènes, le catalogue fidèle de la Bibliothèque, la démonstration de la fausseté de ce catalogue. Tout, mais pour une ligne raisonnable ou une indication exacte, il y aura des millions de cacophonies insensées, de fatras verbaux et d’incohérences. Tout, mais les générations des hommes peuvent passer sans que les rayons vertigineux – les rayons qui oblitèrent le jour et dans lesquels habitent le chaos – leur aient accordé une page tolérable.
L’une des habitudes de l’esprit est d’inventer des imaginations horribles. Il a inventé l’Enfer, il a inventé la prédestination à l’Enfer, il a imaginé les idées platoniciennes, la chimère, la sphynge, les anormaux nombres transfinis (dans lesquels la partie n’est pas moins abondante que le tout), les masques, les miroirs, les opéras, la tératologique Trinité : le Père, le Fils et le Spectre insoluble, articulés en un seul organisme… J’ai tenté, moi, de sauver de l’oubli une horreur subalterne : la vaste Bibliothèque contradictoire, dont les déserts verticaux de livres courent le risque incessant de se changer en d’autres et qui affirment tout, nient tout et confondent tout comme une divinité qui délire.
Jorge Luis Bórges, « La bibliothèque totale », Sur n° 59, août 1939, traduit par Alain Calame
Selon Lasswitz, il n’y aurait pas assez de place dans tout l’Univers pour une telle bibliothèque. Mais l’homme ne s’arrête pas d’écrire : il l’a fait bien avant l’invention de la machine à écrire (et a fortiori de l’ordinateur) : l’écrivain le plus prolifique à ce jour est réputé être l’espagnol Lope de Vega (1562-1635), dont on avait mentionné les « plus de 1800 pièces de théâtre dont il ne nous reste que quelque 400… et (…) nombreuses autres œuvres (poésie, romans, critique, lettres…) ». Il est suivi (selon le Quid) par un auteur anglais de feuilletons, Charles Hamilton (1876-1961), qu’on ne peut soupçonner d’avoir fait usage de générateurs automatiques de textes, de poèmes et d’acrostiches, puisqu’il est décédé en 1961, année où Raymond Queneau publie son Cent mille milliard de poèmes, qui ne sera réalisé en informatique2 que bien plus tard. On constate avec un plaisir teinté de souvenirs évanescents3 que la romancière Enid Blyton (1898-1968), dont les aventures du Club des cinq avaient passionné une partie de notre enfance, s’y trouve en bonne position. Nostalgie, quand tu nous tiens… « Quand je tenais un Club des cinq nouveau, je fermais ma porte, redressais mon traversin, m’installais confortablement, en espérant ne plus bouger avant la fin du livre. Tout le monde savait qu’il ne fallait pas me déranger (…). J’aimais son épaisseur, le contact glacé de sa couverture. Un de mes plaisirs était de sentir la reliure intacte, la bonne odeur de papier entre les pages. » (Serge).
« Concevons qu’on ait dressé un million de singes à frapper au hasard sur les touches d’une machine à écrire et que, sous la surveillance de contremaîtres illettrés, ces singes dactylographes travaillent avec ardeur dix heures par jour avec un million de machines à écrire de types variés. Les contremaîtres illettrés rassembleraient les feuilles noircies et les relieraient en volumes. Et au bout d’un an, ces volumes se trouveraient renfermer la copie exacte des livres de toute nature et de toutes langues conservés dans les plus riches bibliothèques du monde. » – Émile Borel, « Mécanique Statistique et Irréversibilité », J. Phys. 5e série, vol. 3, 1913, pp.189-196. Cité par Infinite Monkeys.L’auteur qui s’y trouve en quatrième position(après l’Indien Baburao4 Arnalkar) est le Brésilien Ryoki Inoué ; médecin de formation, il est l’auteur de 1 075 livres5 et mérite bien son surnom d’« homme-machine à écrire » attribué par le Courrier international (26 avril 2007). Mais selon l’article, il est largement battu par Corín Tellado, auteure de « quelque 5 000 romans à l’eau de rose » (et inconnue du Quid). À force, et grâce aux lois de statistique citées par le grand mathématicien Émile Borel (cf. encadré), il devra bien s’y trouver finalement un chef-d’œuvre ou du moins un paragraphe d’anthologie, indépendamment des dons de l’auteur. Mais il n’est pas donné à tout le monde d’être un Lope de Vega (ni de vivre assez longtemps pour suppléer à ce million de singes), sinon cela se saurait.
Les grands écrivains n’ont pas attendu l’invention de l’ordinateur pour imaginer des machines à générer du texte6. Ainsi, le génial Jonathan Swift décrit en 1726 une machine de ce type se trouvant dans un des ateliers de l’Académie de Laputa, que visite Gulliver :
« Ce métier avait vingt pieds carrés, et sa superficie se composait de petits morceaux de bois à peu près de la grosseur d’un dé, mais dont quelques-uns étaient un peu plus gros. Ils étaient liés ensemble par des fils d’archal très-minces. Sur chaque face des dés étaient collés des papiers, et sur ces papiers on avait écrit tous les mots de la langue dans leurs différents modes, temps ou déclinaisons, mais sans ordre. Le maître m’invita à regarder, parce qu’il allait mettre la machine en mouvement. A son commandement, les élèves prirent chacun une des manivelles de fer, au nombre de quarante, qui étaient fixées le long du métier, et, faisant tourner ces manivelles, ils changèrent totalement la disposition des mots. Le professeur commanda alors à trente-six de ses élèves de lire tout bas les lignes à mesure qu’elles paraissaient sur le métier, et quand il se trouvait trois ou quatre mots de suite qui pouvaient faire partie d’une phrase, il la dictait aux quatre autres jeunes gens qui servaient de secrétaires. Ce travail fut recommencé trois ou quatre fois, et à chaque tour les mots changeaient de place, les petits cubes étant renversés du haut en bas.
Les élèves étaient occupés six heures par jour à cette besogne, et le professeur me montra plusieurs volumes grand in-folio de phrases décousues qu’il avait déjà recueillies et qu’il avait l’intention d’assortir, espérant tirer de ces riches matériaux un corps complet d’études sur toutes les sciences et tous les arts. »
Jonathan Swift , Voyages de Gulliver dans des contrées lointaines, Troisième partie (Voyage à Laputa), chap. 5, pp 270-271. Traduction nouvelle précédée d’une notice par Walter Scott. Illustrations par J.-J. Grandville. Garnier Frères, Paris, m dccc lvi.
Quoi qu’il en soit, Arnalkar écrit ses livres à l’ordinateur (et doit changer de clavier tous les six mois), contribuant ainsi au volume astronomique des contenus numériques produits annuellement, qui ne fait que croître. Y contribuent aussi les grands chantiers de numérisation rétrospective du patrimoine littéraire. L’excellente chaîne de radio publique américaine NPR a réuni avant-hier lors de son émission-phare Talk of the Nation trois acteurs majeurs représentant des approches très diverses concernant cette « utopie », pour reprendre le terme de Bórges.
Michael Hart en est certainement le précurseur (et n’a rien d’un canular, à l’opposé d’un autre précurseur, Hégésippe Simon) : c’est en 1971 qu’il saisit au clavier le tout premier ouvrage (la Déclaration de l’indépendance américaine) de ce qui deviendra le Projet Gutenberg. Celui-ci propose aujourd’hui plus de 20 000 ouvrages, fournis par un travail entièrement bénévole de volontaires aux quatre coins du monde, auxquels se rajoute un nombre bien plus important de contenus contribués par des filiales et des partenaires. Selon Hart, plus le temps passe et plus la part des livres hors copyright baisse, non seulement à cause des volumes croissants de la production, mais des prolongations périodiques des durées de protection pour éviter que des œuvres juteuses ne tombent dans le domaine public (on connaît à ce propos le sort d’une certaine souris). Dans Gutenberg, les textes sont saisis (ou numérisés, puis reconnus) en texte intégral, qui ne préserve pas le format et la mise en page d’origine. Ils passent ensuite plusieurs étapes de relecture. Ceci assure leur haute qualité, mais explique aussi le nombre relativement peu élevé d’ouvrages dans cette collection7. L’utopie selon Hart c’est que chacun puisse posséder, en 2021, une bibliothèque personnelle comprenant un milliard d’ouvrages numériques. Pour cela, il faut continuer à numériser, et à traduire les ouvrages en un grand nombre de langues.
Brewster Kahle établit, en 1996, l’Internet Archive, afin de préserver les contenus changeants et éphémères8 du Web, de tout le Web, ou en tout cas d’une bonne partie. Plus récemment, s’y sont rajoutés des enregistrements sonores et des images animées, ainsi que quelque 200 000 livres (qu’ils numérisent à raison de 12 000 par mois) « hors copyright ou orphelins » (curieuse affirmation, puisqu’on y a trouvé un ouvrage publié par Gallimard en 1960 ; il ne doit pas être le seul). L’objectif est de fournir la possibilité de télécharger tous les contenus qu’ils proposent, contrairement à ce que fait Google qui ne l’autorise pas même pour les ouvrages hors copyright. Selon Kahle, il en coûterait 300 millions de dollars pour numériser un million de livres, chiffre qu’il met en regard des 12 milliards de dollars de l’industrie du livre aux USA. Mais il faut comparer ce qui est comparable : il ne parle pas du coût du maintien de l’infrastructure technologique et de celui de sa migration périodique pour en assurer la compatibilité avec les évolutions technologiques (matériels, logiciels). L’interface servant à consulter les livres est particulièrement bien pensée : la qualité de la numérisation semble uniformément excellente ; les livres s’affichent ouverts à plat, et il suffit de cliquer sur la page de droite ou de gauche pour que celle-ci se tourne. La tranche du livre est représentée, ce qui permet de passer rapidement à une autre partie de l’ouvrage sans avoir à le feuilleter page à page ou à indiquer un numéro de page. Quant à la recherche en texte intégral, elle ouvre le livre à la première occurrence de la réponse, marquée au stabilo, et place des Post-it® annotés aux autres pages. Tout simplement génial. Enfin, tout est prêt pour rajouter un enregistrement sonore du texte lu.
Si Michael Keller est le directeur des bibliothèques de l’université de Stanford, il représentait surtout le « projet Google », avec qui son institution a fait affaire (ce n’est pas un appel aux armes, citoyens) : ils leur fournissent de 1500 à 3000 livres par jour à numériser et à indexer, et reçoivent en retour (en plus de l’ouvrage d’origine…) une copie du fichier informatique. Selon lui, ceci permettra d’assurer une meilleure sauvegarde de ce fonds numérique. Les deux autres participants étaient du même avis, Brewster Kahle allant jusqu’à citer Linus Torvalds (l’inventeur du système Linux) qui aurait dit : « Real Men don’t make backups. They upload it via ftp and let the world mirror it. » (« les mecs qui sont des mecs ne font pas de sauvegardes : ils mettent leurs fichiers sur un serveur ftp, et laissent le reste du monde en faire des copies »). Il en existe de nombreuses variantes, probablement plus apocryphes les unes que les autres, mais y en a-t-il une d’originale ? Et surtout, est-ce si vrai que cela ? Le problème avec cette approche est qu’il n’aborde que le clonage de l’objet, et non pas son évolution nécessaire au fil des évolutions techniques. Sa démultiplication aura d’ailleurs pour effet l’existence d’un nombre incalculable de versions plus incompatibles les unes que les autres, chacun transformant (ou non) la sienne à sa façon. Curieuse « évolution » dans le monde virtuel du texte numérique…
 L’approche que l’Internet Archive a adopté pour présenter ses livres numériques participe de leur réincarnation dans ce qui n’est, pour le moment, qu’un (bon) simulacre du physique. On peut imaginer (comme on n’a pas manqué de le faire) que cette tendance pourra se poursuivre jusqu’à la matérialisation dans un objet physique ressemblant au livre. Mais il existerait une autre approche. Walker Reading Technologies, pépinière américaine qui étudie depuis une dizaine d’années nos capacités de lecture, vient de présenter le résultat de ses recherches ; selon elle, au regard (si l’on peut dire) de la physiologie de l’œil, le livre n’offre pas la meilleure disposition du texte pour une lecture efficace : notre champ de vision et de perception active serait équivalent à ce qu’on voit au travers d’une paille : ainsi, en lisant, notre cerveau doit faire l’effort d’éliminer ce qu’on voit au-dessus et au-dessous des mots que l’on est en train de lire et qui n’a pas de rapport immédiat avec eux (puisque les lignes s’étendent à droite et à gauche hors du champ de vision). Ils proposent donc un produit, Live Ink qui analyse le texte et le redispose à l’écran sous forme de lignes très courtes ; ainsi, ce qui entre dans le champ de vision immédiat a un rapport direct avec ce qu’on lit. La fragmentation est effectuée aussi de façon à rendre plus manifeste la syntaxe du texte – elle ne se fait pas seulement en fonction de la longueur des fragments, mais de la position des parties de la phrase. Les chercheurs indiquent que cette méthode de présentation du texte a des racines très anciennes, en citant Alberto Manguel :
L’approche que l’Internet Archive a adopté pour présenter ses livres numériques participe de leur réincarnation dans ce qui n’est, pour le moment, qu’un (bon) simulacre du physique. On peut imaginer (comme on n’a pas manqué de le faire) que cette tendance pourra se poursuivre jusqu’à la matérialisation dans un objet physique ressemblant au livre. Mais il existerait une autre approche. Walker Reading Technologies, pépinière américaine qui étudie depuis une dizaine d’années nos capacités de lecture, vient de présenter le résultat de ses recherches ; selon elle, au regard (si l’on peut dire) de la physiologie de l’œil, le livre n’offre pas la meilleure disposition du texte pour une lecture efficace : notre champ de vision et de perception active serait équivalent à ce qu’on voit au travers d’une paille : ainsi, en lisant, notre cerveau doit faire l’effort d’éliminer ce qu’on voit au-dessus et au-dessous des mots que l’on est en train de lire et qui n’a pas de rapport immédiat avec eux (puisque les lignes s’étendent à droite et à gauche hors du champ de vision). Ils proposent donc un produit, Live Ink qui analyse le texte et le redispose à l’écran sous forme de lignes très courtes ; ainsi, ce qui entre dans le champ de vision immédiat a un rapport direct avec ce qu’on lit. La fragmentation est effectuée aussi de façon à rendre plus manifeste la syntaxe du texte – elle ne se fait pas seulement en fonction de la longueur des fragments, mais de la position des parties de la phrase. Les chercheurs indiquent que cette méthode de présentation du texte a des racines très anciennes, en citant Alberto Manguel :
« Afin de venir en aide à ceux qui n’avaient guère de talents de lecture, les moines copistes utilisaient une méthode d’écriture dite per cola et commata, dans laquelle le texte était divisé en lignes d’après le sens – forme primitive de ponctuation, qui permettait à un lecteur peu sur de lui de baisser ou d’élever la voix à la fin d’un segment de pensée. (Cette présentation permettait également à un érudit en quête d’un certain passage de le trouver plus facilement.) C’est saint Jérôme qui, à la fin du ive siècle, ayant découvert cette méthode dans des copies de Démosthène et de Cicéron, la décrivit le premier dans son introduction à sa traduction du Livre d’Ezéchiel, en expliquant que “ce qui est écrit per cola et commata communique au lecteur un sens plus évident”. » – Alberto Manguel, Une histoire de la lecture, p. 68.
Des études destinées à mesurer l’efficacité de cette approche ont été effectuées dans des écoles américaines – et non pas avec des lecteurs chevronnés – et ont donné des résultats positifs. Il serait intéressant de savoir si elle est utile pour des textes savants et des lecteurs compétents.
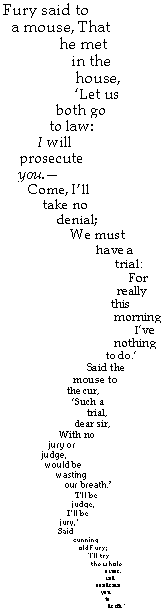 Lewis Carroll y avait-il déjà pensé, lorsqu’il écrivit la forme du texte qu’Alice se représente, en écoutant la narration des malheurs qu’en fait la Souris ? Cette dernière la prévient que son histoire « est bien longue et bien triste », en soupirant et en regardant sa queue. Alice, confondant « narration » (tale, en anglais) et « queue » (tail), se demande ce que cette queue, effectivement longue, a de triste. Mais il est vrai que ce texte se lit aisément, quand on y pense… Plus sérieusement, l’excellent Trésor de la langue française informatisée (TLFi) l’a fait à sa façon : le lecteur peut faire ressortir automatiquement au stabilo les diverses parties du texte : auteur, code grammatical, construction, date, définition, exemple, indicateur, source, synonyme/antonyme, syntagme… Ce qui permet de parcourir rapidement les entrées les plus longues et les plus riches, d’en identifier d’un coup d’œil la structure, bref de l’utiliser d’une façon plus efficace encore. Un must. Ne faudrait-il pas envisager le développement d’interfaces de lecture adaptables plutôt que figées selon un parti-pris particulier, offrant bien plus qu’un simple contrôle sur la mise en page (de ceux généralement disponibles actuellement tels que la taille des polices, le codage, la réorganisation des contrôles, etc.) permettant de faire ressortir la structure profonde du texte à l’aide de couleurs (à l’instar du TLFi), de remise en forme des lignes (comme le propose Walker Reading) ou tout autre moyen pour aider à appréhender la forme et le contenu et à se l’approprier ?9
Lewis Carroll y avait-il déjà pensé, lorsqu’il écrivit la forme du texte qu’Alice se représente, en écoutant la narration des malheurs qu’en fait la Souris ? Cette dernière la prévient que son histoire « est bien longue et bien triste », en soupirant et en regardant sa queue. Alice, confondant « narration » (tale, en anglais) et « queue » (tail), se demande ce que cette queue, effectivement longue, a de triste. Mais il est vrai que ce texte se lit aisément, quand on y pense… Plus sérieusement, l’excellent Trésor de la langue française informatisée (TLFi) l’a fait à sa façon : le lecteur peut faire ressortir automatiquement au stabilo les diverses parties du texte : auteur, code grammatical, construction, date, définition, exemple, indicateur, source, synonyme/antonyme, syntagme… Ce qui permet de parcourir rapidement les entrées les plus longues et les plus riches, d’en identifier d’un coup d’œil la structure, bref de l’utiliser d’une façon plus efficace encore. Un must. Ne faudrait-il pas envisager le développement d’interfaces de lecture adaptables plutôt que figées selon un parti-pris particulier, offrant bien plus qu’un simple contrôle sur la mise en page (de ceux généralement disponibles actuellement tels que la taille des polices, le codage, la réorganisation des contrôles, etc.) permettant de faire ressortir la structure profonde du texte à l’aide de couleurs (à l’instar du TLFi), de remise en forme des lignes (comme le propose Walker Reading) ou tout autre moyen pour aider à appréhender la forme et le contenu et à se l’approprier ?9

À lire
• Terry Butler : Monkeying Around with Text
1 Il fait toutefois l’objet de travaux de recherche de Françoise Willman à l’Université de Nancy 2, ainsi que d’un article de Denis Bousch, « Image de soi et image de l’autre dans Sur deux planètes, un roman d’anticipation de Kurd Laßwitz (1897) », in Françoise Dupeyron Laffay (ed.) : Le livre et l’image dans la littérature fantastique et les œuvres de fiction, Presses de l’Université de Provence, 2004.
2 Elle est disponible sur l’internet, en dépit de la décision de justice qui l’interdit : « En tant que de besoin, faisons interdiction aux défendeurs de mettre l’œuvre de Raymond Queneau à la disposition des utilisateurs du réseau Internet ce sous astreinte de 10.000 francs par infraction constatée » (Ordonnance de référé, Tribunal de grande instance de Paris, 5 mai 1997). Nous n’en fournirons donc pas l’adresse.
3 À tel point que j’étais persuadé qu’ils avaient été publiés dans la série Bibliothèque verte. Que nenni, c’était la Bibliothèque rose, où ils entrèrent en 1958, après avoir paru initialement dans la Collection Ségur-Fleuriot (selon François Lebrun).
4 Et non « Baboorao », comme l’écrit le Quid. Mais il ne serait pas à une inexactitude près : il y est indiqué que cet auteur est né en 1907, tandis qu’il est né en 1906 et décédé en 1996 (source : ambassade de l’Inde à Manille). Dans la même page, il est fait mention de « Julien Greene » au Julien Green (qu’ils doivent savoureusement confondre, au moins depuis 2003, avec Graham Greene…). Plus bas, on peut lire : « D’après le professeur E. Gaede, il y aurait eu en France, depuis l’invention de l’imprimerie, de 30 000 à 70 000 écrivains qui ont écrit en tout 500 000 livres. » Il s’agit sans doute d’Édouard Gaède, qui a publié en 1972 L’Écrivain et la société : dossier d’une enquête (publié par le Centre d’études de la civilisation du 20e). Il est curieux que le Quid de 2007 ne mentionne pas de références plus récentes, s’il s’agit bien de celle-ci. Mais c’est ce dernier chiffre qui est curieux : selon les chiffres clés du secteur du livre publiés par le ministère de la culture (la version intégrale est aussi disponible en ligne), 340 269 nouveaux titres ont été édités entre 1985 et 2005 (donc hors réimpressions). En comparant ces deux sources, il en ressortirait que le nombre de nouveaux titres publiés au cours des vingt dernières années s’élève à 68% du nombre de titres écrits durant les quelque 550 années précédentes. S’agit-il vraiment des mêmes catégories, et si oui, comment s’explique cette explosion ? Ah, si Paul Otlet avait fini son travail, on aurait la réponse. Le Quid s’est d’ailleurs commis dans des déformations autrement plus graves, que ce soit à propos du négationnisme de la Shoah ou de celui du génocide des Arméniens.
5 Selon son site (on ne trouve que huit de ses titres au catalogue de la Bibliothèque nationale du Brésil – mais comme il a publié sous une quarantaine de pseudonymes, ce n’est pas si surprenant). Le Quid de 2007 n’en annonce que 1 046, même chiffre que celui de l’édition de 2003. À se demander pourquoi ils en sortent un chaque année…
6 Ni d’ailleurs pour la musique : le célèbre Musikalische Wurfelspiele (jeu de dés musical) en do majeur K 516f de Mozart n’était pas unique en son temps, et consistait à produire un morceau de musique à l’aide d’un assemblage aléatoire d’éléments (chez Mozart : composés de deux mesures).
7 C’est ce qui distingue ce projet des grands projets contemporains, qui numérisent automatiquement en « mode image » les ouvrages, puis effectuent, toujours automatiquement, une reconnaissance du texte, qui ne sera pas présenté au lecteur (vu sa qualité parfois inégale, surtout pour les ouvrages plus anciens, ce n’est pas forcément critiquable), mais qui servira à la recherche dans les contenus. Le lecteur, lui, verra à l’écran l’image (et ne pourra donc effectuer de copier-coller du texte).
8 On estimait, à la fin des années 1990, la durée de vie moyenne d’une page Web à quelques dizaines d’heures – sa disparition pouvant être due à des causes variées : changement d’adresse, suppression de la page, suspension d’un site, faillite de l’hébergeur… D’autre part, les contenus de l’Archive sont eux-mêmes soumis parfois à l’obsolescence : on a pu constater que certains sites Web – disparus depuis longtemps du Web mais préalablement archivés dans ce système – en avaient aussi disparu quelques années plus tard. Ainsi va le monde.
9 Ceci nécessite évidemment de la part du logiciel d’avoir la capacité à identifier cette structure, ce qui peut être accompli de façon automatisée (du moins partiellement, mais mieux qu’avant) plutôt qu’uniquement manuelle.
